
Improving Accuracy and Trust in Agentic Analytics
Semantic layers improve accuracy. Semantic lineage earns trust.

Cube held an event this week and a lot of emphasis was on agentic analytics. One session that stood out for me was the one where Cube did research on the accuracy of responses by LLMs with and without a light semantic layer in context. The results are that a semantic layer does improve response accuracy.
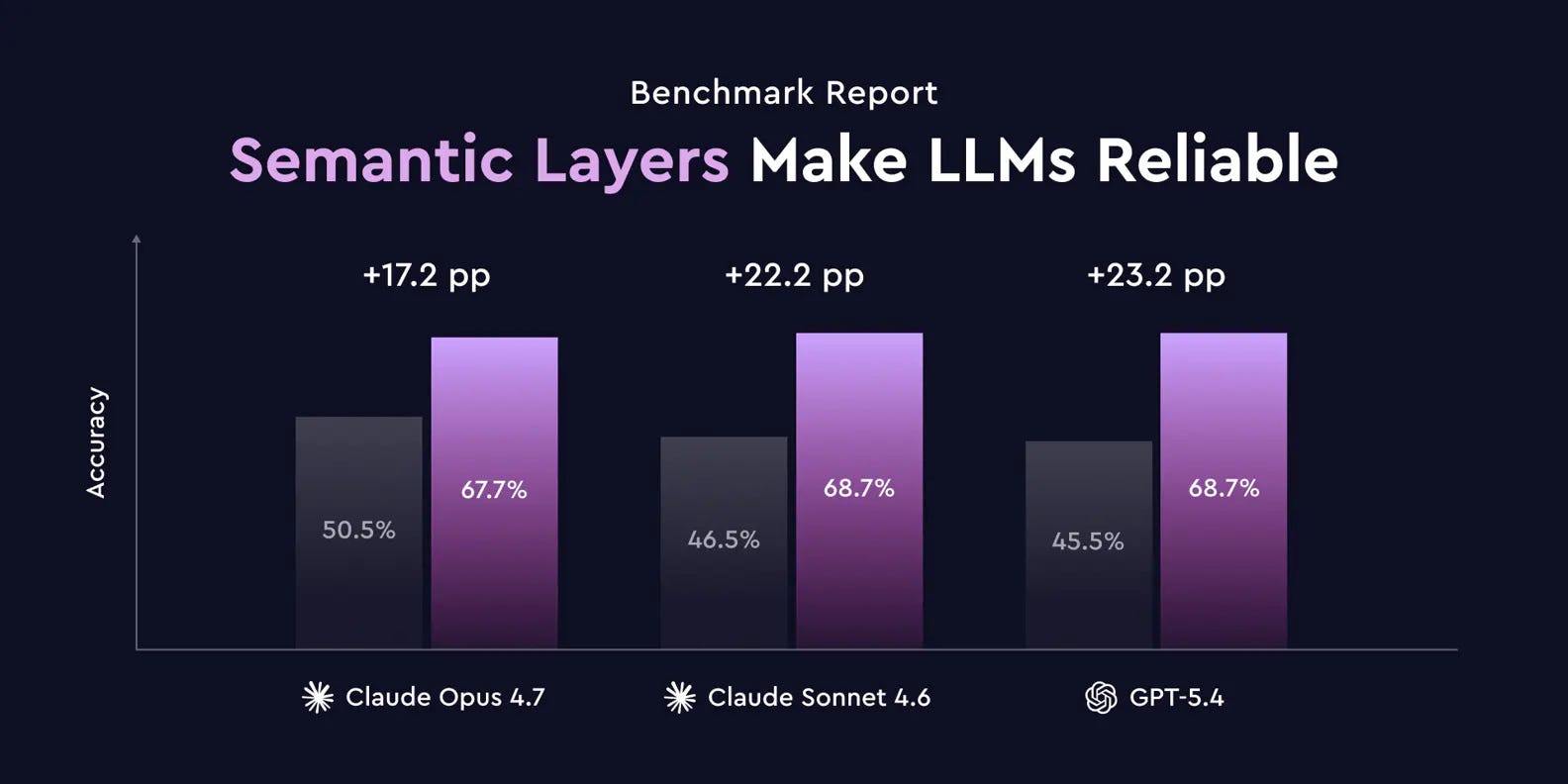
But the underlying story is that a 68% accuracy is not great either. Imagine having users conversing with your data and each question leads to an error rate of 32%. Compound that over a couple of questions, and you have a situation where the trust between the user and your data is broken.
A one-shot natural language to SQL query will have poor performance, as Cube demonstrated. But as you introduce agents, with their capabilities to “reason”, try-out queries, explore the data assets, you will be improving the accuracy of their outputs.
Now introduce a rich semantic layer and those agents should be able to return highly accurate answers.
Will that be enough though?
Let’s say I ask the following question: “what is our current profit for this quarter and how does it track against our targets?” That is a lot for an agent to unpack.
What is the current quarter?
What is the definition of profits?
What are those targets?
Do we have all of the data points needed to serve this?
Where is the right dataset / data interface to get this data?
Now let’s say the agent was able to get the data, interpret it and give you an answer. You might look at the numbers, squint your eyes and ask: “Wait, are you including retail stores and ecommerce? Cause our targets should be higher than that. Also, I think your definition of profits might be wrong, what is yours?”
You know that this is the conversation that is going to happen. It’s not that the agent didn’t do a proper job in its first run. It’s just that users are, rightly so, highly skeptical of the data they receive.
Every user wants to challenge the data until they learn to trust it
The question then is: are semantic models enough context for the agent to perform to a level of accuracy that you would be willing to productionize this?
Beyond the Semantic Layer
Let’s go back to those follow-up questions: “Wait, are you including retail stores and e-commerce? Cause our targets should be higher than that. Also, I think your definition of profits might be wrong, what is yours?” Those are challenges. And the agent might find the answer to those in some form or another. Maybe the dataset that was used had a “channel” field with a breakdown by retail store and e-commerce, which will allow the agent to answer that question confidently. But let’s say profits are an aggregate at that level, and the definition isn’t actually written down anywhere.
Then it becomes a guess-game. And you know how LLMs do like to sound highly confident when sharing their guesses.
So it might say: “Ah, profits are the revenue minus costs” and it’s going to be highly confident with that. But the user might retort: “actually, you should also subtract returns” and the agent might come back with: “You’re absolutely right, you legend, profits are actually revenue minus costs minus returns”.
Now the skeptical user wouldn’t stop there. They’d either tear this chat apart with a spray of detailed questions the agent would be baffled by. Or they’d brush this aside as a useless piece of sh**, and be done with it.
A semantic layer is just this: a thin slice of your business meaning. Whenever you try to dig deeper, the agent will need to resort to all sorts of acrobatics to answer questions that it doesn’t have the answers to.
And that erodes trust.
Semantic Lineage
What if you had a graph of all semantic decisions that were injected into your data?
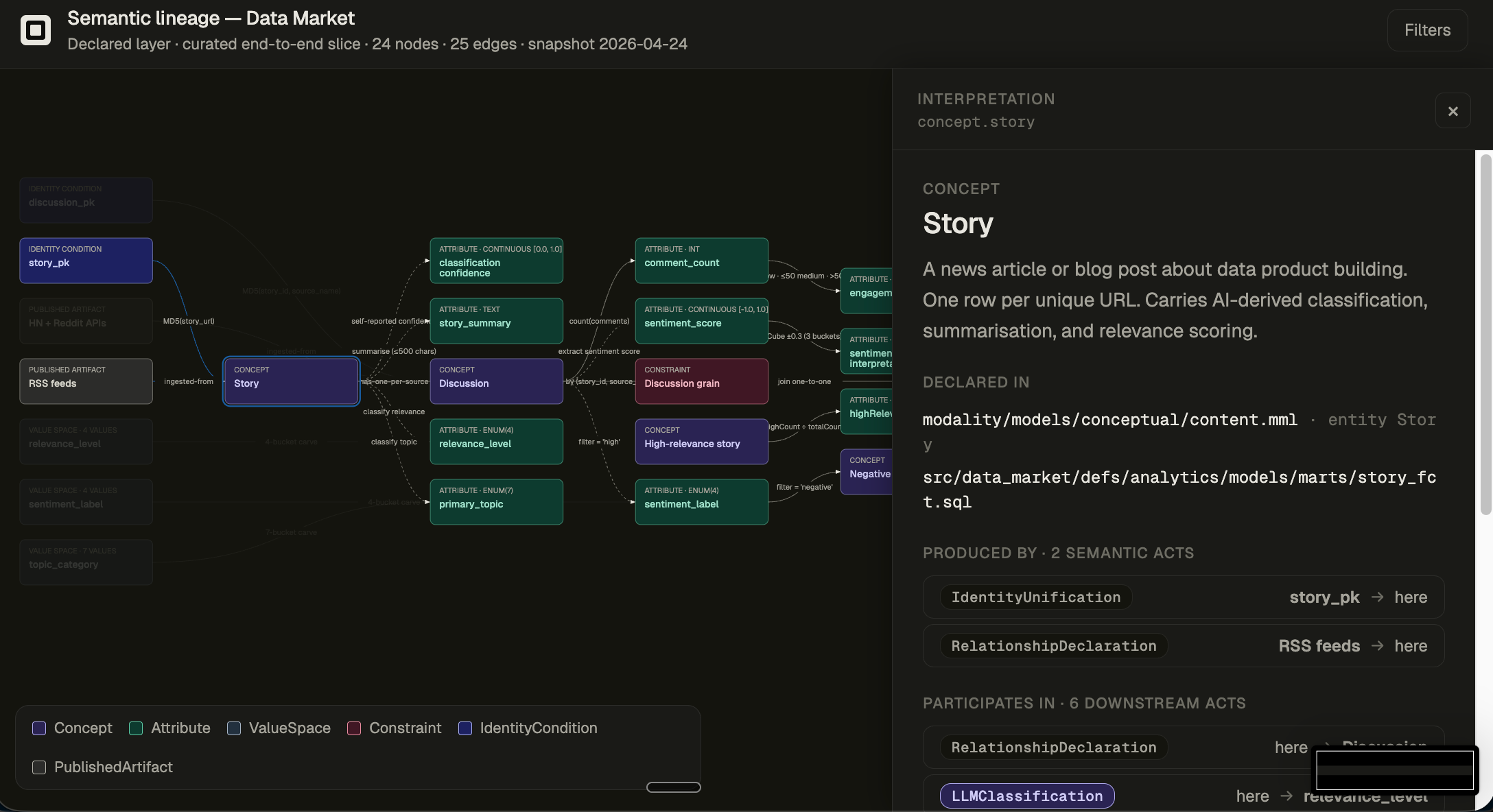
Above is a DAG of all the semantic processing happening on top of my Data Market platform (https://blog.republicofdata.io/the-7-layers-of-market-intelligence-in-a-box/). It captures a small slice of what a Story actually is in the system: where stories come from, how we decide one story is the same as another, how we classify their relevance, and how we filter the stream down to the ones worth caring about.
Let’s go through a real-world example. One question I’d reasonably ask an agent on top of the Data Market is:
“What’s been dominating our coverage this week?”
Say the agent comes back with: “Engineering Pipelines is the top category, with about 38% of stories. ML & Analytics is second.”
Same instinct kicks in. I squint. “Engineering Pipelines? My own feed has been nothing but AI/ML stuff for two weeks. Either your classifier is wrong or your buckets don’t match what I’m actually reading.”
This is where the semantic lineage earns its keep. The graph shows what’s sitting behind the word “category”:
attr.primary_topicis a single label per story, assigned by an LLM.It picks from
vs.topic_category, a fixed 7-bucket carve we wrote ourselves: infrastructure, engineering pipelines, ML & analytics, quality & observability, governance & security, product & org, tooling & DX.Each story gets exactly one primary topic. An article about “ML training pipelines” can land in either bucket depending on how the LLM reads it.
attr.classification_confidenceis the LLM’s own self-report. It’s a vibe, not a calibrated probability.
So when the agent says “Engineering Pipelines is dominant”, what that really means is: the LLM, given a 7-way choice we picked, leaned toward Engineering Pipelines on more articles than ML & Analytics, with self-reported confidence that nobody has audited. The graph doesn’t fix that. It just makes the call visible, so the conversation can move from “is the answer right?” to “are seven buckets still the right cut, and should ML pipelines be its own bucket?”
Now multiply that by every other word in the original question. “Coverage” counts only stories where the LLM managed to assign a primary topic at all (if it returned NOT_RELEVANT or null, they’re gone from the denominator). “This week” is first-seen-by-us, not published-by-them. “Dominating” is a raw count, not weighted by reader attention or downstream amplification.
Most of this is in a semantic model. None of it is in the agent’s context window unless something puts it there. The semantic lineage graph does.
Semantic Refinement
Challenging your data should lead to trust. And once you’ve built that trust, the skeptical user keeps going. They start poking at the semantic decisions baked into the data platform itself.
You don’t just want users saying: “Great, I know how much profit we made last quarter and how it tracked against targets.” You want them coming out the other side more educated: “Not only do I know those numbers, but I know exactly how those numbers came to be. And I need to have a chat with the finance team. Some of the assumptions in our ETL don’t match how they think about this.”
The age of agents shouldn’t be where questions go to die in confusion. It should be the opposite. Agents are the surface area that finally forces us to put the full semantic context of our data somewhere it can be challenged, traced, and improved.
So the next time a user squints at an agent’s answer, treat it as a gift. They’re telling you exactly which semantic decision needs to be visible.